
Im ersten Teil einer Serie von AWX Beiträgen zeige ich, wie man AWX grundsätzlich so einrichtet, dass die Kernfunktionen genutzt werden können. Ziel ist es, gegen ein System ein Ansible ad-hoc Kommando auszuführen.
AWX ist relativ simpel im Aufbau, nur auf den ersten Blick wirkt es komplex. Es gibt folgende Kernkomponenten, die für ein Basissetting ausreichen:
- Credentials
Egal wohin kommuniziert werden soll, ein Git, Ziel-Hosts etc., hier befinden sich die Login-Informationen - Projects
Hier werden die Ansible-Projekte erstellt, zumeist auf Basis eines (Git) Repositories - Inventories
Beinhaltet ein importiertes Ansible-Inventory (mit Hosts usw.) aus einem entsprechenden Projekt - Hosts
Alle Hosts aus den Inventories
Wenn diese Dinge konfiguriert sind, ist man bereits in der Lage ad-hoc Kommandos gegen Zielsysteme auszuführen. Folgendes wird beschrieben:
- Einrichten eines Credentials für einen Git-Server und Zielsysteme
- Einrichten eines Projektes für das Ansible-Inventory (das spätere Code-Repository wird noch nicht benötigt)
- Inventory einrichten
- Ein ad-hoc Kommando gegen ein Zielsystem aus dem Inventory ausführen
Credential für einen Git-Server
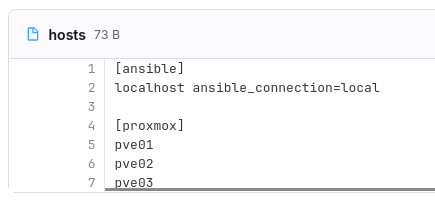
Ich setze hier einige Dinge voraus: Es gibt auf dem Git-Server einen Service-Account mit konfigurierten SSH Zugang per PublicKey. Zusätzlich gibt es ein Repository, dass mindestens eine hosts Datei mit Zielsystemen beinhaltet:
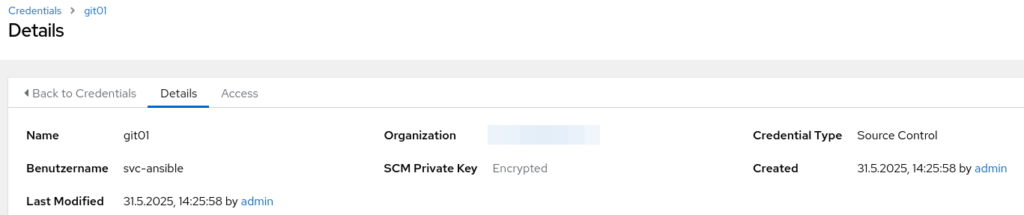
In AWX muss ein neues Credential vom Typ „Source Control“ erstellt werden. Der Name ist frei wählbar. Es wird in diesem Fall kein Passwort hinterlegt, sondern der PrivateKey passend zum PublicKey auf dem Git-Server:
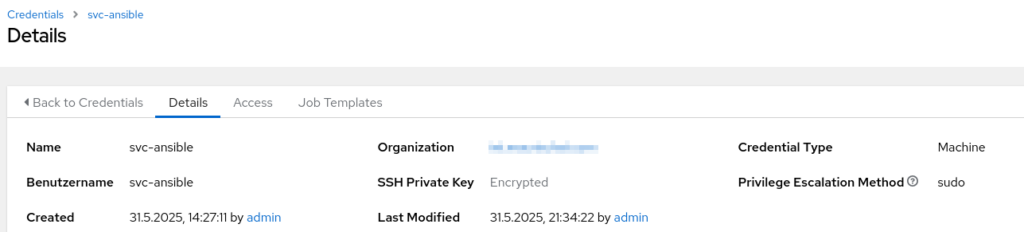
Credential für Zielsysteme (Hosts)
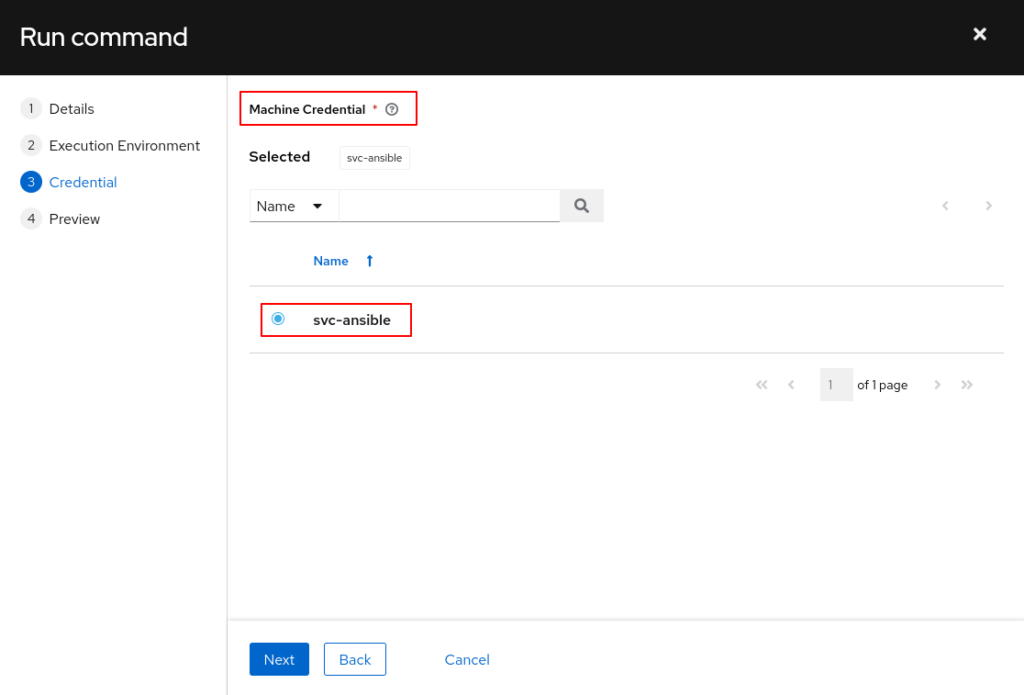
Dies ist der Account, der später auf allen Zielsystemen für die Ausführung von Ansible Prozessen genutzt werden soll. Ich habe hierfür einen separaten Service-Account erstellt. Dieses Credential ist vom Typ „Machine“. Zusätzlich muss als Privilege Escalation Method „sudo“ angegeben werden (was impliziert, dass auf den Zielsystemen sudo konfiguriert ist und der Service-Account Mitglied). Auch hier findet die Authentifizierung per SSH-Key statt.
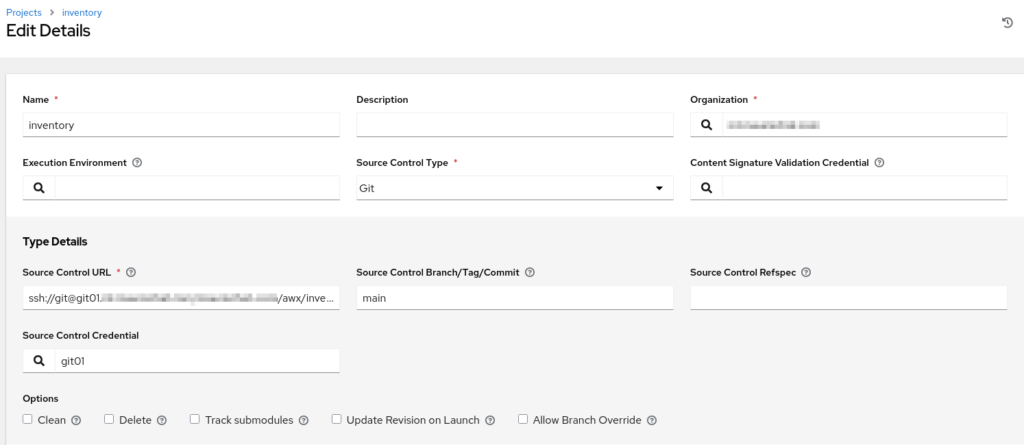
Einrichten des Projektes für das Ansible-Inventory
Mit dem Project für das Inventory wird der Import (bzw. die Synchronisierung) des Repositories mit dem Ansible-Inventar vom Git-Server ermöglicht. Der Source Control Type ist hier „Git“. Die URL wird per SSH angesprochen, nicht per HTTP(S). Als Source Control Credential nimmt man das vorab erstellte Credential für den Git-Server aus einer Auswahlliste. Der Name ist wieder frei wählbar.
Sofern alles stimmt, kann das Repository synchronisiert werden.

Nach dem Sync ist auch nur das Repository synchronisiert, es gibt noch kein tatsächliches Inventory mit dem man arbeiten kann.
Erstellen/Einrichten des Inventories
Für die Erstellung muss nur ein Name angegeben werden (frei wählbar). Die Magie passiert in der Konfiguration des Inventory. Hier muss man unter „Sources“ angeben, dass das Inventory aus dem Projekt geholt werden soll, welches das Repository vom Git-Server synchronisiert. Dies passiert mittels des Typs „Sourced from a Project“. Zusätzlich muss man mit angeben, welche Datei das eigentliche Inventory beinhaltet (hier „hosts“).
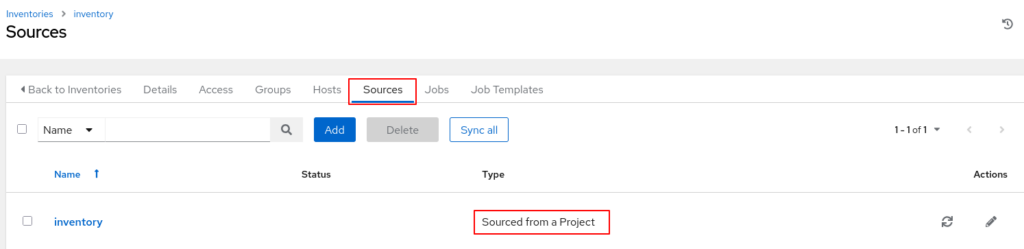
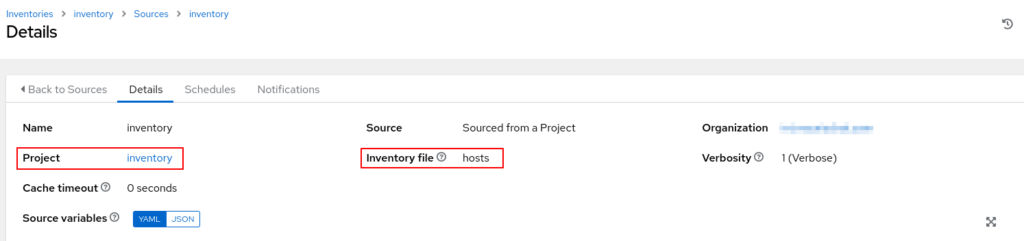
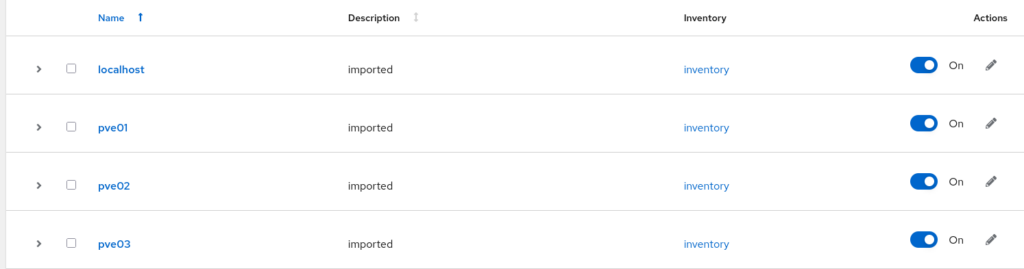
Wenn anschließend eine erste Synchronisierung erfolgreich gelaufen ist, tauchen automatisch die Systeme aus dem Inventory unter „Hosts“ auf.

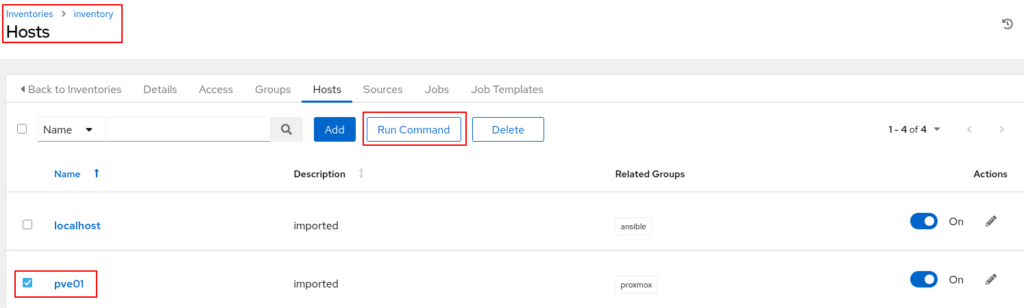
Ein ad-hoc Kommando ausführen
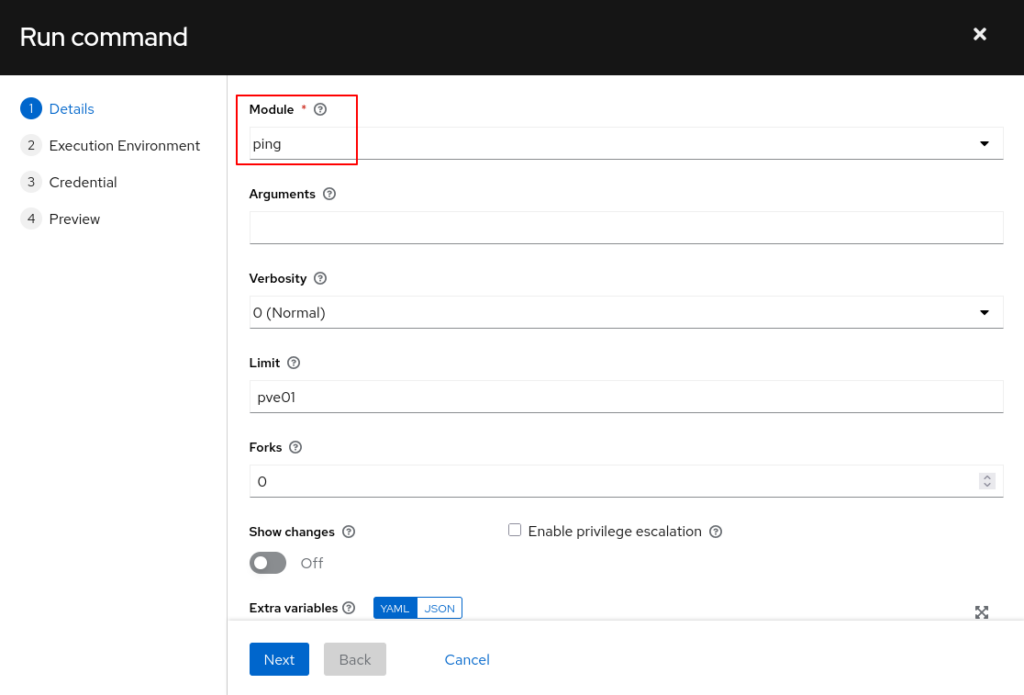
Über das Inventory und die darin enthaltenen Hosts kann nun ein ad-hoc Kommando ausgeführt werden. Der absolute Basis-Befehl dürfte wohl der Ansible-Ping sein. Dieser prüft die Verfügbarkeit eines Zielsystems.
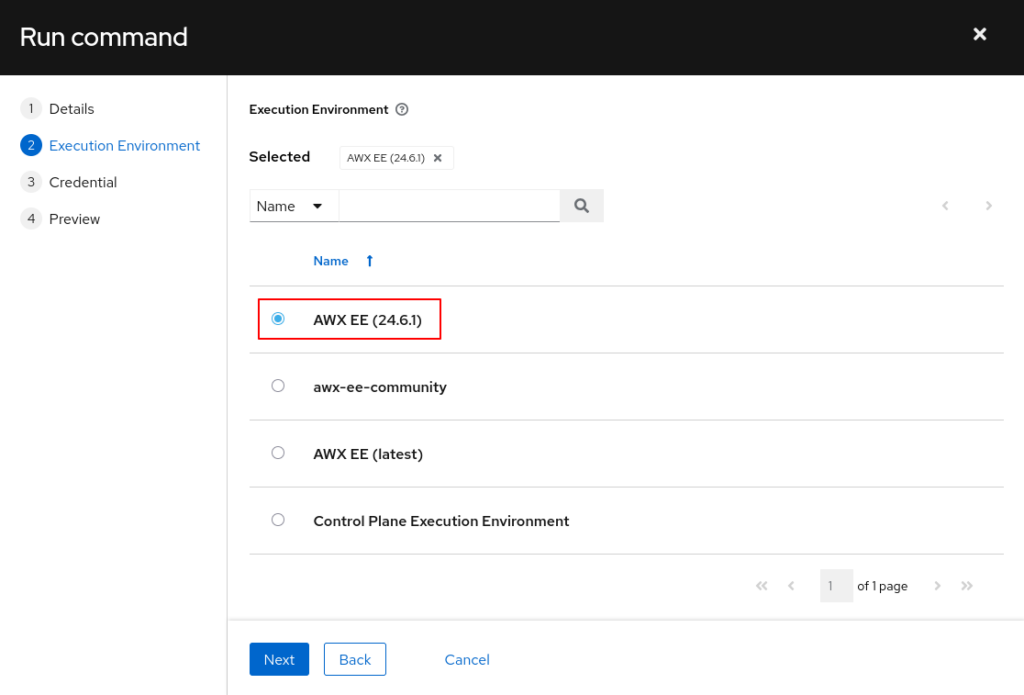
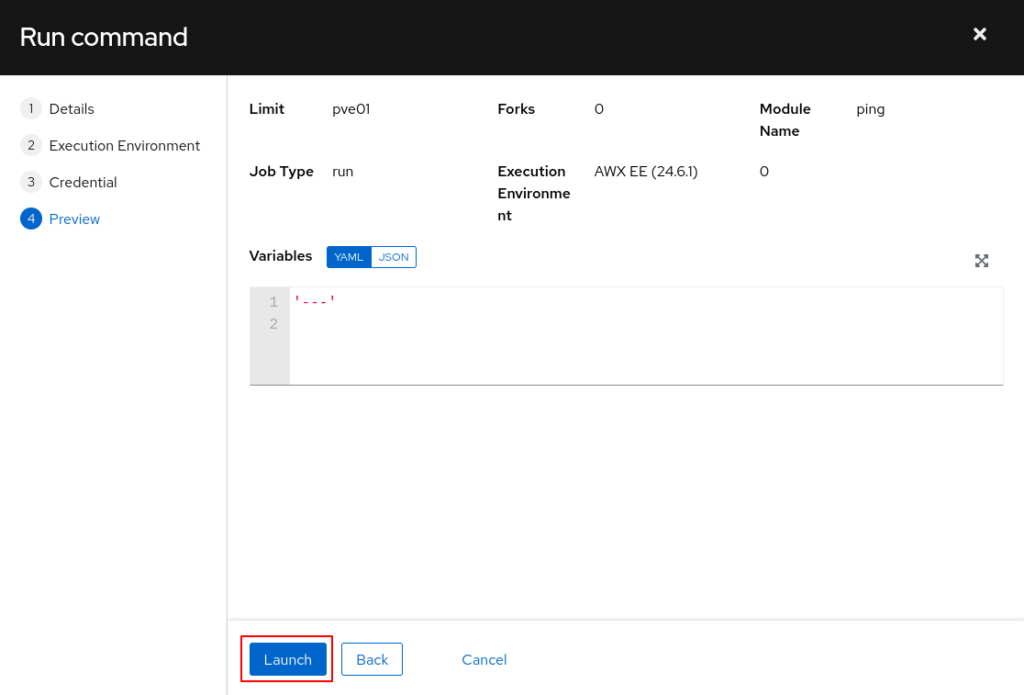
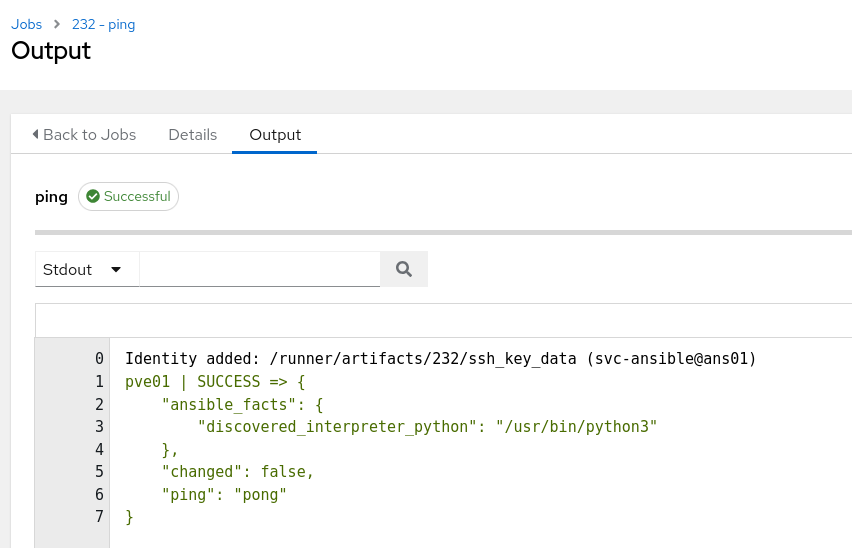
Und das war es auch schon 🙂
An diesem Punkt ist AWX einsatzbereit. Im nächsten Teil kommt das Ansible-Code Repository hinzu und es wird ein einfaches Playbook ausgeführt.
